nlp (上)
NLP从0到-1
文本预处理
文本处理的基本方法
分词
流行的中文分词包 jieba,支持多种分词方式 (精确模式 全模式 搜索引擎模式),支持繁体分词,自定义词典分词
精确模式 jieba.cut
试图将句子最精确地切开,适合文本分析
全模式
把句子中所有的可以成词的词语都扫描出来,速度非常快,但不能消除歧义
搜索引擎模式 jieba.cut_for_search
在精确模式的基础上,对长词再次切分,提高召回率
使用自定义词典jieba.load_userdict
添加自定义词典后,jieba能够准确地识别词典中的词汇,提高识别准确率
词典格式:每一行分成三部分,词语,词频(可省略),词性(可省略), 用空格隔开,排序不可颠倒
具体词性含义参考jieba词性对照表
词性标注 import jieba.posseg
- 词性:语言中对词的一种分类方法,以语法特征为主要依据、兼顾词汇意义对词进行划分的结果,常见的词性有14种,如:名词,动词,形容词等
- 顾名思义,词性标注(Part-Of-Speech tagging.简称POS)就是标注出一段文本中每个词汇的词性
- 词性标注的作用:词性标注以分词为基础,是对文本语言的另一个角度的理解,因此也常常成为AI解决NLP领域高阶任务的重要基础环节
命名实体识别
- 命名实体:通常我们将人名,地名,机构名等专有名词统称命名实体.如:周杰伦,黑山县,孔子学院,24辊方钢矫直机
- 顾名思义,命名实体识别(Named Entity Recognition,简称NER)就是识别出一段文本中可能存在的命名实体
- 命名实体识别的作用:同词汇一样,命名实体也是人类理解文本的基础单元,因此也是AI解决NLP领域高阶任务的重要基础环节
文本张量表示方法
one-hot编码
独热编码,略
Word2vec
- word2vec是一种流行的将词汇表示成向量的无监督训练方法,该过程将构建神经网络模型,将网络参数作为词汇的向量表示,它包含CBOW和skipgram两种训练模式
- CBOW(Continuous bag of words)模式:给定一段用于训l练的文本语料,再选定某段长度(窗口)作为研究对象,使用上下文词汇预测目标词汇
- skipgram模式:给定一段用于训练的文本语料,再选定某段长度(窗口)作为研究对象,使用目标词汇预测上下文词汇
Word2vec 的训练和使用
本文采用gensim库而非原生fasttext,数据来源 http://mattmahoney.net/dc/enwik9.zip(未处理)
1
2
3
4
5
6
7
8
9
10
11
12
13from gensim.models.fasttext import FastText
from gensim.models import KeyedVectors
# 训练模型
model = FastText(corpus_file= './fil9', epoch= 1, batch_words= 1000)
model.wv.save_word2vec_format('./fil9.bin', binary= True)
# 加载模型
model = KeyedVectors.load_word2vec_format('./fil9.bin', binary= True)
# 查询
result = model['the']
print(f"Result:{result}")Word Embedding nn.Embedding
- 通过一定的方式将词汇映射到指定维度(一般是更高维度)的空间
- 广义的word embedding包括所有密集词汇向量的表示方法,如之前的word2vec,即可认 为是word embedding的一种
- 狭义的word embedding是指在神经网络中加入的embedding层,对整个网络进行训l练的同时产生的embedding矩阵(embedding层的参数),这个embedding矩阵就是训练过程中所有输入词汇的向量表示组成的矩阵
文本语料的数据分析
标签数量分布
在深度学习模型评估中,我们一般使用ACC作为评估指标,若想将ACC的基线定义在50%左右,则需要我们的正负样本比例维持在1:1左右否则就要进行必要的数据增强或数据删减
句子长度分布
通过绘制句子长度分布图,可以得知我们的语料中大部分句子长度的分布范围,因为模型的输入要求为固定尺寸的张量,合理的长度范围对之后进行句子截断补齐(规范长度)起到关键的指导作用
词频统计与关键词词云
词频统计与关键词词云能够帮助我们快速理解文本中的关键信息和主题
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49from itertools import chain
import jieba
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import jieba.posseg as pseg
import wordcloud
sentences = pd.read_csv("./nlp/案例2/train.csv", sep=",")
# 获得句子标签分布
# sns.countplot(x= 'label', data= sentences, hue= 'label')
# plt.show()
# 获得句子长度分布
sentences['lenth'] = sentences['sentence'].apply(lambda x: len(x))
# 绘制直方图
# sns.histplot(x= 'lenth', data= sentences, hue= 'lenth', )
# plt.show()
# 获得训练集的词汇集合
train_veb = set(chain(*map(lambda x: jieba.lcut(x), sentences['sentence'])))
print(f"训练集共包含不同词汇的数量为:{len(train_veb)}")
print(f"训练集的词汇集合为:{train_veb}")
# 获得训练集上正样本的词汇集合
words = set(chain(*map(lambda x: jieba.lcut(x), sentences[sentences['label'] == 1]['sentence'])))
print(f"训练集上正样本的词汇集合为:{words}")
def get_a_list(sentence):
list = []
for value in pseg.lcut(sentence):
if value.flag == 'a':
list.append(value.word)
return list
# 获得指定词性的词汇集合
# word_cloud = set(chain(*map(lambda x: get_a_list(x), sentences[sentences['label'] == 1]['sentence'])))
# print(f"训练集上正样本的词汇集合为:{word_cloud}")
keywords = " ".join(words)
word_cloud = wordcloud.WordCloud(font_path="./nlp/案例2/SimHei.ttf", background_color="white", max_words=1000, max_font_size=50, random_state=42)
word_cloud.generate(keywords)
plt.figure()
plt.imshow(word_cloud, interpolation="bilinear")
plt.axis("off")
plt.show()
文本特征处理
添加n-gram特征
给定一段文本序列,其中n个词或字的相邻共现特征即n-gram特征,常用的n-gram特征是bi-gram和tri-gram特征,分别对应n为2和3
例如:有A = “我爱你” B = “你爱她”
A 分完词后 [‘我’, ‘爱’, ‘你’] -> 添加 2-gram -> [‘我’, ‘爱’, ‘你’, ‘我爱’, ‘爱你’]
同理 B -> 添加 2-gram -> [‘你’, ‘爱’, ‘她’, ‘你爱’, ‘爱她’]
去重所有词 -> [‘我’, ‘爱’, ‘你’, ‘她’, ‘我爱’, ‘爱你’, ‘你爱’, ‘爱她’]
A1 -> [1, 1, 1, 0, 1, 1, 0, 0] B1 -> [0, 1, 1, 1, 0, 0, 1, 1]
-> 计算相似性
1
2def creat_ngram_set(input_list: list, ngram_range: int):
return set(zip(*[input_list[i:] for i in range(ngram_range)]))文本长度规范
一般模型的输入需要等尺寸大小的矩阵,因此在进入模型前需要对每条文本数值映射后的长度进行规范,此时将根据句子长度分布分析出覆盖绝大多数文本的合理长度,对超长文本进行截断,对不足文本进行补齐(一般使用数字0),这个过程就是文本长度规范
1
2
3
4
5
6
7
8def padding(input_list: list, cut_length: int):
result = []
for l in input_list:
if len(l) > cut_length:
result.append(l[:cut_length])
else:
result.append(l + [0] * (cut_length - len(l)))
return result
数据增强方法
回归数据增强法
回译数据增强目前是文本数据增强方面效果较好的增强方法,一般基于google、有道等翻译接口将文本数据翻译成另外一种语言(一般选择小语种)之后再翻译回原语言,即可认为得到与原语料同标签的新语料,新语料加入到原数据集中即可认为是对原数据集数据增强
回译数据增强存在的问题:在短文本回译过程中,新语料与原语料可能存在很高的重复率,并不能有效增大样本的特征空间
RNN及其变体
环神经网络(Recurrent Neural Network)是一种专门处理序列数据的神经网络。与传统的前馈神经网络不同,RNN具有“循环”结构,能够处理和记住前面时间步的信息,使其特别适用于时间序列数据或有时序依赖的任务。时间序列数据是指在不同时间点上收集到的数据,这类数据反映了某一事物、现象等随时间的变化状态或程度。这是时间序列数据的定义,当然这里也可以不是时间,比如文字序列,但总归序列数据有一个特点——后面的数据跟前面的数据有关系
应用:
- 自然语言处理(NLP):文本生成、语言建模、机器翻译、情感分析等
- 时间序列预测:股市预测、气象预测、传感器数据分析等
- 语音识别:将语音信号转换为文字
- 音乐生成:通过学习音乐的时序模式来生成新乐曲
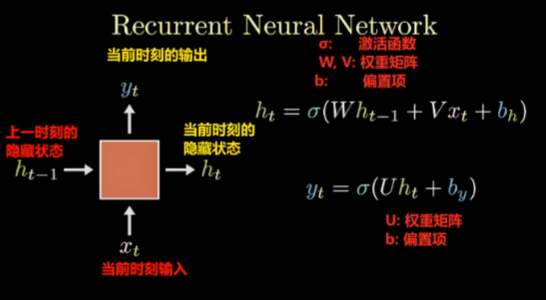
传统RNN
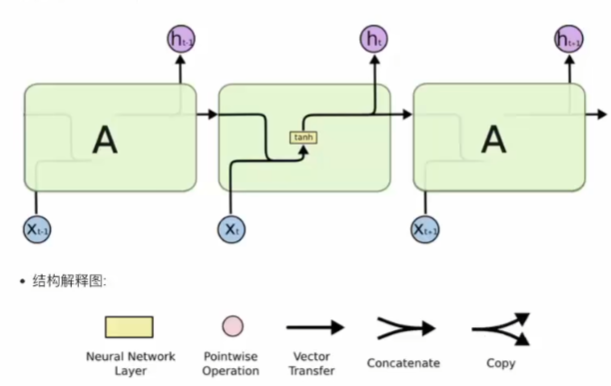
由图易得内部结构计算公式 ht = tanh (Wt[Xt, ht − 1] + bt)
1 | |
优点:计算资源要求低,在短序列任务上性能和效果都表现优异
缺点:解决长序列的表现很差,原因是在反向传播时,过长的序列会导致梯度的计算异常,发生梯度消失或爆炸
LSTM
LSTM(Long Short-Term Memory) 也称长短时记忆结构,属于 RNN 的变体,相比下能够有效捕捉长序列之间的语义关联,缓解梯度消失或爆炸现象。同时LSTM的结构更复杂,可以分为四部分:
遗忘门
选择性的遗忘部分信息,计算公式: ft = σ(Wf ⋅ [ht − 1, xt] + bf)
输入门
选择性记忆
it = σ(Wi ⋅ [ht − 1, xt] + bi)
C̃t = tanh (WC ⋅ [ht − 1, xt] + bC)
细胞状态
即 Ct (长期记忆)
输出门
即 ht (短期记忆)
ot = σ(Wo ⋅ [ht − 1, xt] + bo)
ht = ot ⋅ tanh (Ct)
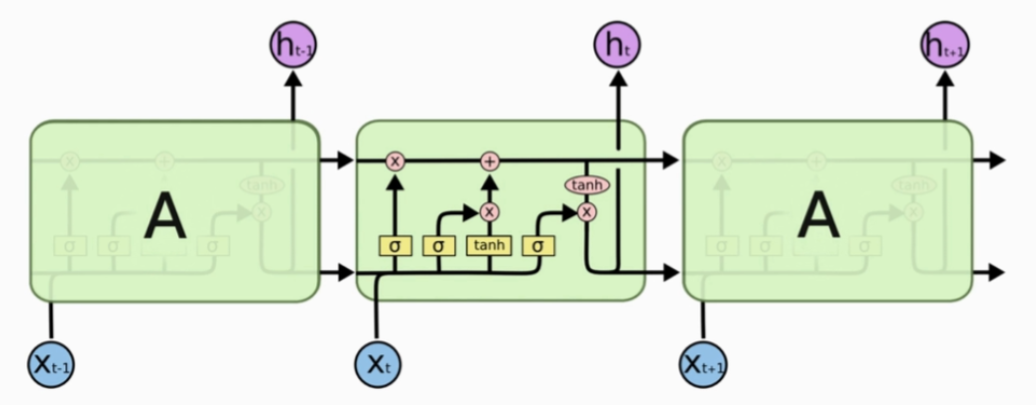
Bi-LSTM:进行从左到右和从右到左两次LSTM处理,将结果拼接后作为最终输出。这样能够捕捉语言语法中一些特定的前置或后置特征,增强语义关联
1 | |
GRU
GRU(Gated Recurrent Unit)也称门控循环单元结构,它也是传统RNN的变体,同LSTM一样能够有效捕捉长序列之间的语义关联,缓解梯度消失或爆炸现象.同时它的结构和计算要比LSTM更简单,它的核心结构可以分为两个部分去解析:
更新门
zt = σ(Wz ⋅ [ht − 1, xt])
重置门
rt = σ(Wr ⋅ [ht − 1, xt])
$$ \tilde h_t=\tanh(W\cdot [r_t\cdot h_{t-1},x_t]) \\ h_t=(1-z_t)\cdot h_{t-1} + z_t \cdot \tilde h_t $$
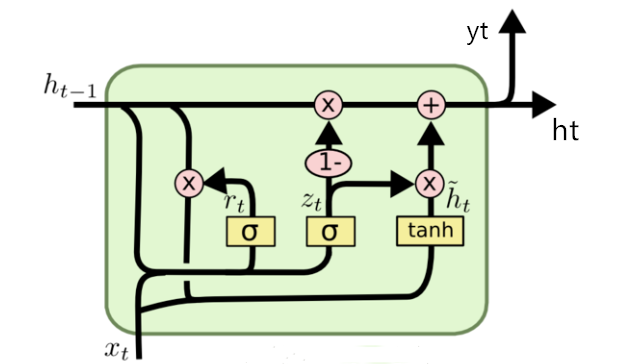
Bi-GRU:与 Bi-LSTM 类似
1 | |
RNN 案例 人名分类器
简介:以一个人名为输入,使用模型帮助我们判断它最有可能是来自哪一个国家的人名,这在某些国际化公司的业务中具有重要意义,在用户注册过程中,会根据用户填写的名字直接给他分配可能的国家或地区选项,以及该国家或地区的国旗,限制手机号码位数等等
数据来源:https://download.pytorch.org/tutorial/data.zip
拿到数据后,我们需要进行预处理
1 | |
模型构建与训练
1 | |
注意力机制
seq2seq (sequence to sequence)架构翻译任务
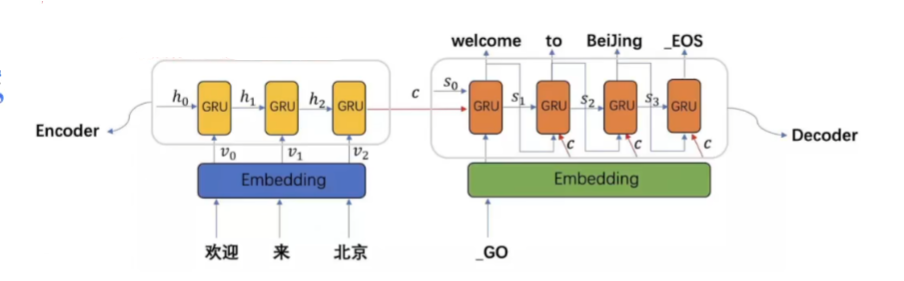
- seq2seq模型架构包括三部分,分别是encoder(编码器)、decoder(解码器)、中间语义张量c
- 早期在解决机器翻译这一类seq2seq问题时,通常采用的做法是利用一个编码器(Encoder)和一个解码器(Decoder)构建端到端的神经网络模型,但是基于编码解码的神经网络存在两个问题:
- 如果翻译的句子很长很复杂,比如直接一篇文章输进去,模型的计算量很大,并且模型的准确率下降严重
- 在翻译时,可能在不同的语境下,同一个词具有不同的含义,但是网络对这些词向量并没有区分度,没有考虑词与词之间的相关性,导致翻译效果比较差
- 针对这样的问题,注意力机制被提出
分类
- 通俗来讲就是对于模型的每一个输入项,可能是图片中的不同部分,或者是语句中的某个单词分配一个权重,这个权重的大小就代表了我们希望模型对该部分一个关注程度。这样一来,通过权重大小来模拟人在处理信息的注意力的侧重,有效的提高了模型的性能,并且一定程度上降低了计算量
- 深度学习中的注意力机制通常可分为三类:软注意(全局注意)、硬注意(局部注意)和自注 意(内注意)
- 软注意机制(Soft/Global Attention):对每个输入项的分配的权重为0-1之间,也就是某些部 分关注的多一点,某些部分关注的少一点,因为对大部分信息都有考虑,但考虑程度不一样,所以相对来说计算量比较大
- 硬注意机制(Hard/Local Attention):对每个输入项分配的权重非0即1,和软注意不同,硬注意机制只考虑那部分需要关注,哪部分不关注,也就是直接舍弃掉一些不相关项。优势在于可以减少一定的时间和计算成本,但有可能丢失掉一些本应该注意的信息
- 自注意力机制(Self/Intra Attention):对每个输入项分配的权重取决于输入项之间的相互作 用,即通过输入项内部的“表决”来决定应该关注哪些输入项。和前两种相比,在处理很长的输入时,具有并行计算的优势
Soft Attention(最常见)
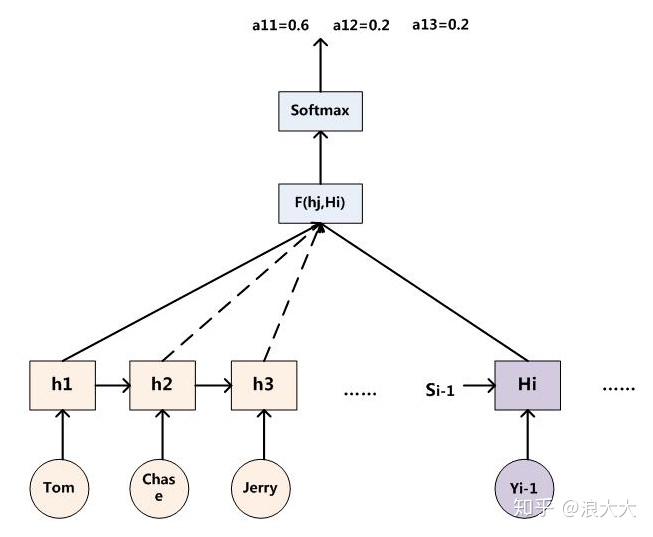
- 将Source中的构成元素看作是一系列的数据对,给定Target中的某个元素Query,通过计算Query和各个Key的相似性或者相关性,即权重系数;然后对Value进行加权求和,并得到最终的Attention数值。将本质思想表示成公式如下:
$$ Attention(Query,Source)=\sum_{i=1}^mSimilarity(Query,Key_i)\cdot Value_i $$
- 深度学习中的注意力机制中,Source中的Key和Value合二为一,指向的是同一个东西,也即输入句子中每个单词对应的语义编码
- 以一个搜索引擎的检索为例。使用某个Query去搜索引擎里搜索,搜索引擎里面有好多文章,每个文章的全文可以被理解成Value;文章的关键性信息是标题,可以将标题认为是Key。搜索引擎用Query和那些文章们的标题(Key)进行匹配,看看相似度(计算Attention Score)。我们想得到跟Query相关的知识,于是用这些相似度将检索的文章Value做一个加权和,那么就得到了一个新的信息,新的信息融合了相关性强的文章们,而相关性弱的文章可能被过滤掉
Hard Attention
相比于软注意力的求和,硬注意力一般有:
- 选择注意力分布中,分数最大的那一项对应的输入向量作为Attention机制的输出
- 根据注意力分布进行随机采样,采样结果作为Attention机制的输出
Self Attention
自注意力是注意力机制的一种特殊形式,它的查询(Q)、键(K)、值(V)都来自同一个输入序列(Q = K = V),通过计算序列内部各元素之间的相关性(每每两个token计算),来捕获序列内部的依赖关系
2"The animal didn't cross the street because it was too tired"这里的“it”应该指向“animal”而不是“street” 自注意力能够直接建立这种远程关联
常见注意力计算规则
将 Q、K 进行纵轴合并,做一次线性变换,再使用 softmax 处理获得结果,最后与 V 做张量乘法
Attention(Q, K, V) = Softmax(Linear([Q, K])) ⋅ V
将 Q、K 进行纵轴合并,做一次线性变换,再使用 tanh 激活,进行内部求和,再使用 softmax 处理获得结果,最后与 V 做张量乘法
Attention(Q, K, V) = Softmax(sum(tanh(Linear([Q, K])))) ⋅ V
将Q与K的转置做点积运算,然后除以一个缩放系数,再使用softmax处理获得结果最后与V做张 量乘法
$Attention(Q,K,V)=Softmax(\frac{Q\cdot K^T}{\sqrt{d_k}})\cdot V$
注意力机制的作用
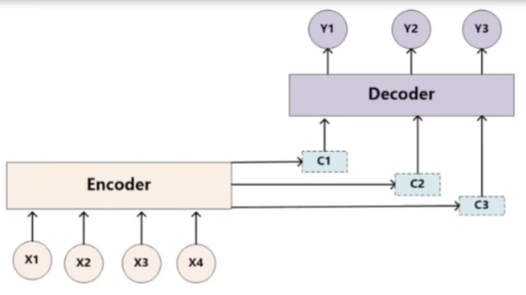
- 在解码器端的注意力机制:能够根据模型目标有效的聚焦编码器的输出结果,当其作为解码器的输入时提升效果,改善以往编码器输出是单一定长张量,无法存储过多信息的情况
- 在编码器端的注意力机制:主要解决表征问题,相当于特征提取过程,得到输入的注意力表示。一般使用自注意力(self-attention)
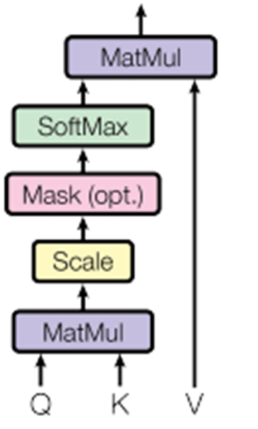
注意力机制实现步骤与样例
- 第一步:根据注意力计算规则,对Q,K,V进行相应的计算
- 第二步:根据第一步采用的计算方法,如果是拼接方法,则需要将Q与第二步的计算结果再进行拼接,如果是转置点积,一般是自注意力,Q与V相同,则不需要进行与Q的拼接
- 第三步:最后为了使整个attention机制按照指定尺寸输出,使用线性层作用在第二步的结果上做一个线性变换,得到最终对Q的注意力表示
1 | |
英译法案例
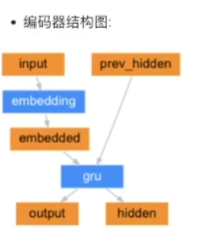
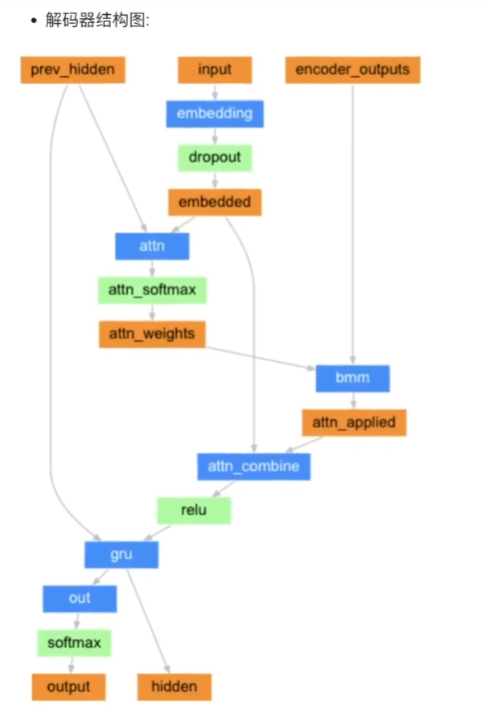
teacher_forcing:
在训练时,将真实的前一时刻标签(ground truth)作为当前时刻的输入,而不是使用模型自己上一时刻的预测输出
作用:
- 加速收敛 使用真实标签作为输入,避免了模型在训练早期因预测不准而累积误差,使训练更稳定、更快收敛。
- 减少训练方差 如果使用模型自身的预测作为下一步输入,早期模型的错误会不断传递,导致梯度更新方向波动大,训练困难。Teacher Forcing 固定了输入序列,降低了方差。
- 解决曝光偏差(Exposure Bias)问题的折中 在推理时,模型只能使用自己生成的序列作为后续输入,而训练时如果一直用 Teacher Forcing,会导致训练与推理条件不一致,这称为曝光偏差。 Teacher Forcing 是一种折中:训练时用真实数据引导,推理时切换为自回归生成。 > 作者此案例仓库:https://github.com/Suzuran28/Eng2Fra
1 | |