神经网络从入门到入坟
神经网络从入门到入坟
神经网络
神经网络概念
人工神经网络(Aritifical Neural Network 简称 ANN 也简称 NN)
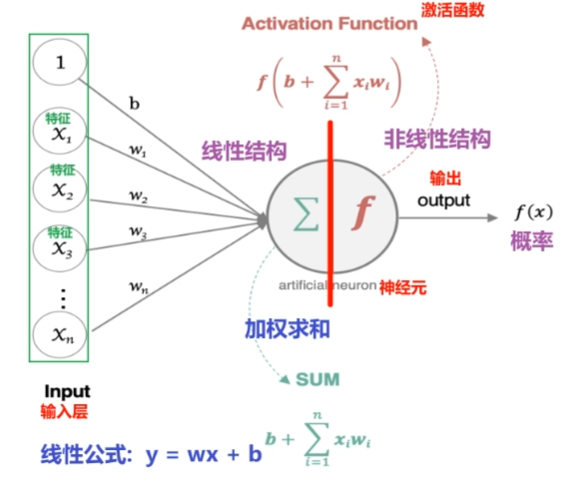
机器学习:输入数据 → 线性模型,预测值 → Sigmoid激活函数 → 概率
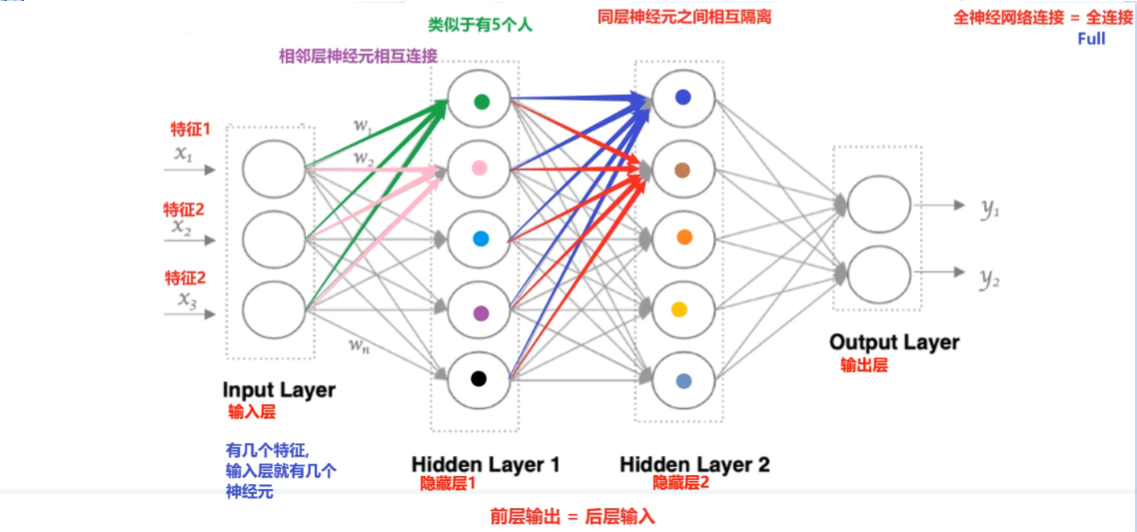
神经网络:输入层 → 隐藏层 → 输出层
构建神经网络:神经网络由多个神经元组成,构建神经网络就是在构建神经元,神经网络的构成包括输入层,隐藏层和输出层
全连接
神经网络内部状态值和激活值:每一个神经网络工作时,前向传播会产生两个值,内部状态值(加权求和值) 和激活值;反向传播时会产生激活值梯度和内部状态值梯度
激活函数
激活函数:激活函数用于对每层的输出数据进行变换,进而为整个神经网络注入了非线性因素。此时,神经网络就可以拟合各种曲线
- 没有引入非线性因素的网络等价与使用一个线性模型来拟合
- 通过给网络输出增加激活函数,实现引入非线性因素,使得网络模型可以逼近任意函数,提升网络对复杂问题的拟合能力
Sigmoid 激活函数:
公式: $f(x)=\frac{1}{1+e^{-x}}$
求导: f′(x) = f(x)(1 − f(x))
图像:
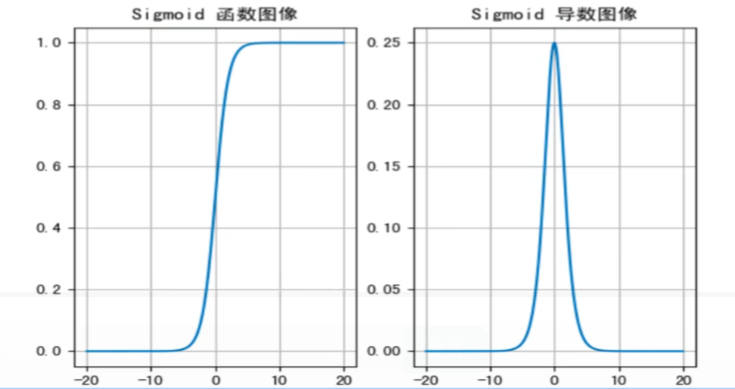
- sigmoid 函数能将任意输入映射到 (0, 1) 之间,当输入的值 < − 6 或者 > 6 时,意味着输入任何值得到的结果都差不多,这样会丢失部分信息
- 通常输入值在 [ − 6, 6] 之间才会有明显差距,在 [ − 3, 3] 之间才会有比较好的效果
- 通过导数图像,可以发现导数值域为 [0, 0.25] ,当输入 < − 6 或 > 6 时,导数接近 0,此时网格参数更新极其缓慢,或者无法更新
- 一般来说,sigmoid 网络在 5 层之内就会产生梯度消失现象。而且,该激活函数并不是以 0 为中心的,所以实践中这种函数使用很少。 sigmoid函数一般只用于二分类的输出层
tanh 激活函数:
公式:$f(x)=\frac{1-e^{-2x}}{1+e^{-2x}}$
求导:f(x) = 1 − f2(x)
图像:
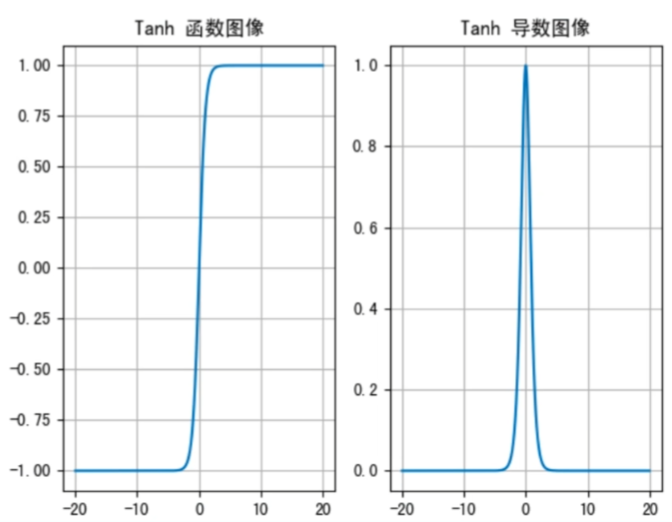
- tanh 函数将输入映射到 [ − 1, 1] 之间,图像以 0 为中心, 在 0 点对称,当输入的 < − 3 或 > 3 时将被映射为 − 1 或者 1 。其导数范围 (0, 1) ,当输入的 < − 3 或 > 3 时,导数近似 0
- 与 sigmoid 相比,它是以 0 为中心的,且梯度相对比较大,使得收敛速度更快,减少了迭代次数。然而,tanh 两侧的导数也为 0, 同样会造成梯度消失
- 若使用时可在隐藏层使用 tanh 函数,输出层使用 sigmoid 函数
ReLU 激活函数:
公式:f(x) = max (0, x)
求导:f′(x) = 0或1
图像:
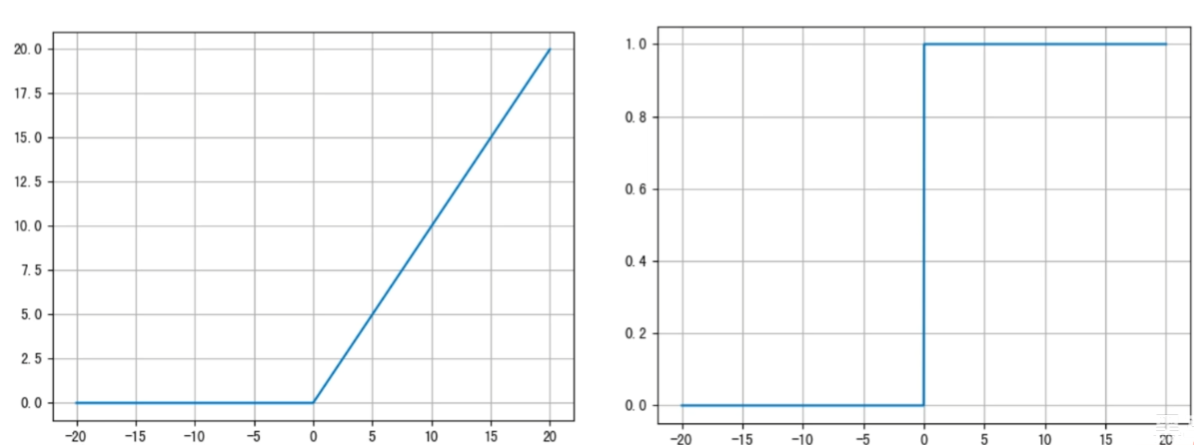
ReLU 函数将小于 0 的值映射为 0,而大于 0 的值保持不变,它更重视正信号,忽视负信号,这种激活函数运算更为简单,能够提高模型的训练效率
当 x < 0,ReLU导数为 0,而当 x > 0时,则不存在饱和问题。所以,ReLU 能够在 x > 0 时保持梯度不衰减,从而缓解梯度消失问题。然而,随着训练的推进,部分输入会落入小于 0 的区域,导致权重无法更新。这种现象称为“神经元死亡”
ReLU 是目前最常用的激活函数,与 sigmoid 相比,优势是:
采用 sigmoid 函数,计算量大(指数计算),反向传播求误差梯度时,计算量相对大,而采用 ReLU 激活函数,整个过程的计算量节省很多。sigmoid 函数反向传播时,很容易出现梯度消失,从而无法完成深层网络的训练。ReLU 会使一部分神经元的输出为 0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生
(默认情况下) ReLU 只考虑正样本,可以使用 LeakyReLU,PReLU 来考虑正负样本
LeakyReLU: $$ f(x)= \begin{cases} 0.01x &if\ x<0 \\ x &if\ x\ge0\\ \end{cases} \ \ \ \ \ \ \ \ \ f'(x)= \begin{cases} 0.01 &if\ x<0 \\ 1 &if\ x\ge0 \end{cases} $$ PReLU: $$ f(\alpha,x)= \begin{cases} \alpha x &if\ x<0 \\ x &if\ x\ge0\\ \end{cases} \ \ \ \ \ \ \ \ \ \ \ \ \ f'(\alpha,x)= \begin{cases} \alpha &if\ x<0 \\ 1 &if\ x\ge0 \end{cases} $$
SoftMax 激活函数:
SoftMax 用于多分类过程中,它是二分类函数 sigmoid 在多分类上的推广,目的是 将多分类的结果以概率的形式展现出来
公式:$softmax(z_i)=\frac{e^{z_i}}{\sum_j e^{z_j}}$
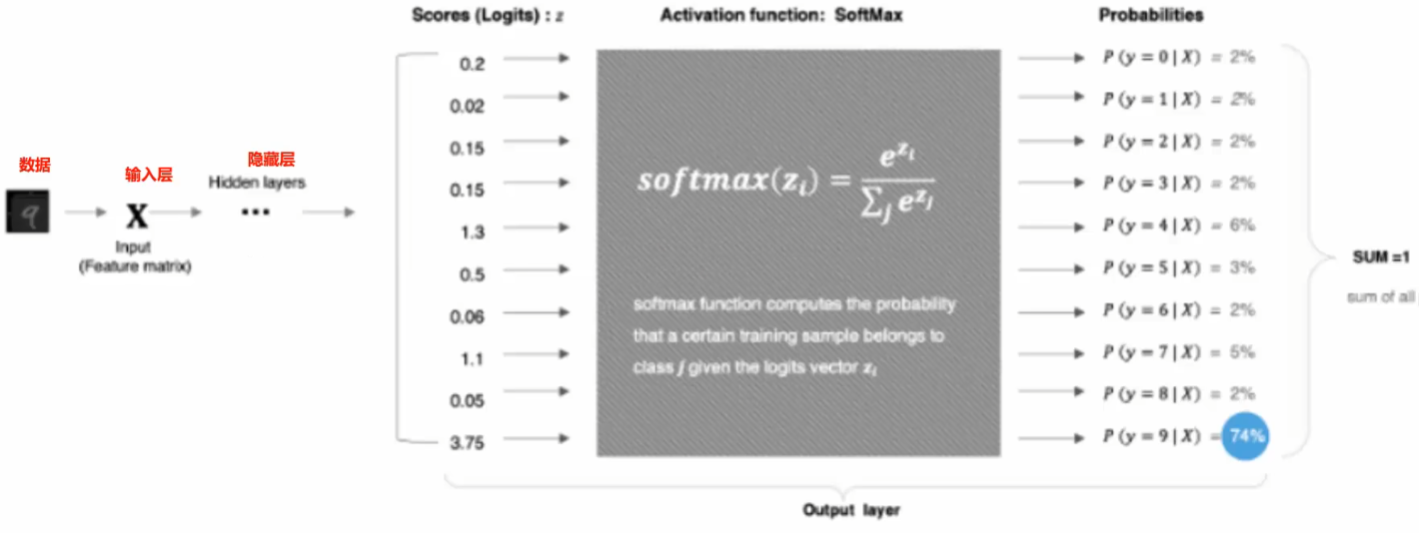
对于隐藏层:
- 优先选择 ReLU 函数
- 如果效果不好,尝试 LeakyReLU 或者 PReLU
- 使用 ReLU 时要注意神经元死亡问题
- 少使用 sigmoid 函数,可以尝试 tanh 函数
对于输出层:
- 二分类问题选择 sigmoid 激活函数
- 多分类问题选择 softmax 激活函数
- 回归问题选择 identify (f(x) = x)激活函数
参数初始化
我们在构建网络之后,网络中的参数是需要初始化的。我们需要初始化的参数主要有权重和偏置,偏置一般初始化为 0 即可,而对权重的初始化则会更加重要。 参数初始化的作用:
- 防止梯度消失或爆炸:初始权重值过大或过小会导致梯度在反向传播中指数级增大或缩小。
- 提高收敛速度:合理的初始化使得网络的激活值分布适中,有助于梯度高效更新。
- 保持对称性破除:权重的初始化需要打破对称性,否则网络的学习能力会受到限制。
- 均匀分布初始化 torch.nn.init.uniform_()
- 权重参数初始化从区间均匀随机取值,默认为 (0, 1)。可以设置在 $(\frac{-1}{\sqrt d}, \frac{1}{\sqrt d})$ 均匀分布中生成当前神经元的权重,其中 d 为神经元的输入数量
- 优点:能有效打破对称性
- 缺点:随机选择范围不当可能导致梯度问题
- 适用场景:浅层网络或低复杂度模型
- 正态分布初始化 torch.nn.init.normal_()
- 随机初始化从均值为 0,标准差是 1 的高斯分布中取样,使用一些很小的值对参数 w 进行初始化
- 全 0 初始化 torch.nn.init.zeros_()
- 优点:实现简单
- 缺点:无法打破对称性,所有神经元更新方向相同,无法有效训练
- 适用场景:几乎不使用,仅用于偏置项的初始化
- 全 1 初始化 torch.nn.init.ones_()
- 优点:实现简单
- 缺点:无法打破对称性,所有神经元更新方向相同,无法有效训练。会导致激活值在网络中呈指数增长,容易出现梯度爆炸
- 适用场景:测试或调试
- 固定值初始化 torch.nn.init.constant_()
- 优点:实现简单
- 缺点:无法打破对称性,所有神经元更新方向相同,无法有效训练。会导致激活值在网络中呈指数增长,容易出现梯度爆炸
- 适用场景:测试或调试
- kaiming 初始化,也叫 HE 初始化
- 专为 ReLU 和其变体设计,考虑到 ReLU 激活函数的特性,对输入维度进行缩放
- HE 初始化分为正态分布的 HE 初始化(kaiming_normal_())、均匀分布的 HE 初始化(kaiming.uniform())
- 正态分布的 HE 初始化
- 从 [0, std] 中抽取样本,$std=\sqrt{\frac{2}{fan\_in}}$
- 均匀分布的 HE 初始化
- 从 [ − limit, limit] 中的均匀分布中抽取样本,$limit=\sqrt{\frac{6}{fan\_in}}$
- fan_in 输入神经元的个数
- 优点:适合 ReLU,能保持梯度稳定
- 缺点:对非 ReLU 激活函数效果一般
- 适用场景:深层网络(10层及以上),使用 ReLU、Leaky ReLU 激活函数
- xavier 初始化,也叫 Glorot 初始化
- 该方法也有 2 种,分别为正态分布的 xavier 初始化(xavier_normal_())、均匀分布的 xavier 初始化(xavier.uniform())
- 正态分布的 xavier初始化
- 从 [0, std] 中抽取样本,$std=\sqrt{\frac{2}{fan\_in + fan\_out}}$
- 均匀分布的 xavier 初始化
- 从 [ − limit, limit] 中的均匀分布中抽取样本,$limit=\sqrt{\frac{6}{fan\_in+fan\_out}}$
- fan_in 输入神经元的个数,fan_out 输出神经元的个数
- 优点:适用于 Sigmoid、Tanh 等激活函数,解决梯度消失问题
- 缺点:对 ReLU 等激活函数表现欠佳
- 适用场景:深层网络(10层及以上),使用 Sigmoid、Tanh 激活函数
如何选择参数初始化
- 激活函数的选择:根据激活函数的类型选择对应的初始化方法
- Sigmoid/Tanh:xavier 初始化
- ReLU/Leaky ReLU:kaiming 初始化
- 神经网络模型的深度:
- 浅层网络:随机初始化即可
- 深层网络:需要考虑方差平衡,如 xavier 或 kaiming 初始化
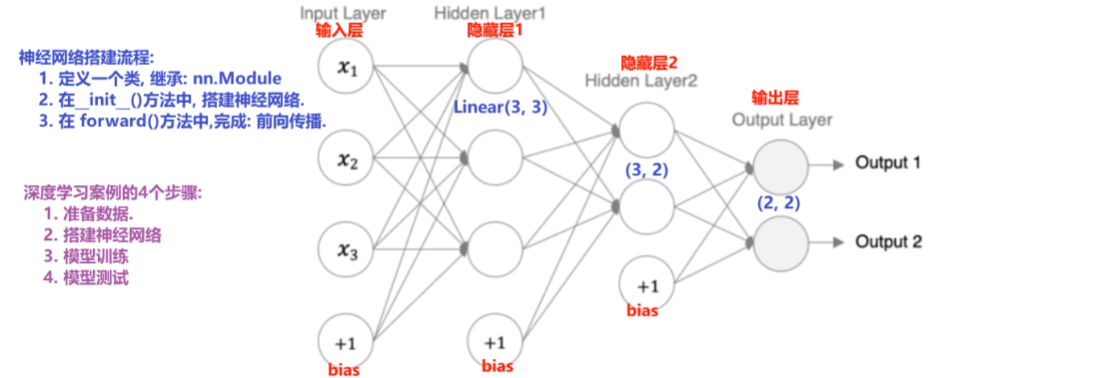
神经网络的搭建和参数计算
在pytorch中定义深度神经网络其实就是层堆叠的过程,继承自 nn.Module,实现两个方法:
__init__方法中定义网络中的层结构,主要是全连接层,并进行初始化forward 方法,在实例化模型的时候,底层会自动调用该函数。该函数中为初始化定义的 layer 传入数据,进行前向传播等
损失函数
多分类任务损失函数
在多分类任务通常使用 softmax 将 logits 转换为概率的形式,所以多分类的交叉熵损失也叫 softmax 损失。多分类交叉熵损失 = softmax() + 损失计算,使用这个损失函数,输出层就不用额外调用 softmax()
公式:$L=-\sum_{i=1}^n y_i\log(S(f_\theta(x_I)))$
- y 是样本 x 属于某一个类别的真实概率
- 而 f(x) 是样本属于某一类别的预测分数
- S 是 softmax 激活函数
- L 用来衡量真实值 y 和预测值 f(x) 之间差异性的损失结果
API:nn.CrossEntropyLoss()
二分类任务损失函数
处理二分类任务时,我们不再使用 softmax 激活函数,而是使用 sigmoid 激活函数,二分类需要手动调用 sigmoid函数
公式:L = − ylog ŷ − (1 − y)log (1 − ŷ)
- y 是样本 x 属于某一个类别的真实概率
- 而 ŷ 是样本属于某一类别的预测分数
- L 用来衡量真实值 y 和预测值 ŷ 之间差异性的损失结果
API:nn.BCELoss
回归任务损失函数—— MAE 损失函数
MAE 也称为 L1 Loss,由于 L1 Loss 具有稀疏性,为了惩罚较大的值,因此常常将其作为正则项添加到其他 Loss 中作为约束。L1 Loss 最大的问题是梯度在零点不平滑,导致会跳过极小值
公式:$L=\frac{1}{n}\sum_{i=1}^n|y_i-f_\theta(x_i)|$
API:nn.L1Loss()
回归任务损失函数—— MSE 损失函数
MSE 也称为 L2 Loss ,或欧氏距离,L2 Loss 也常常作为正则项。当预测值与目标值相差很大时,梯度容易爆炸
公式:$L=\frac{1}{n}\sum_{i=1}^n(y_i-f_\theta(x_i))^2$
API:nn.MSELoss()
回归任务损失函数—— Smooth L1 损失函数
Smooth L1 指的是光滑之后的 L1,在 [ − 1, 1] 之间实际上就是 L2 损失,解决了 L1 不平滑问题,在 [ − 1, 1] 区间外,实际上就是 L1 损失,这样就解决了离群点梯度爆炸的问题
公式: $$ smooth_{L_1}(x=) \begin{cases} 0.5x^2 &if\ \ |x|<1\\ |x|-0.5 &otherwise \end{cases} $$ API:nn.SmoothL1Loss()
网络优化方法
梯度下降
如果学习率过小,那么每次训练得到的效果都很小,增大训练的时间成本。如果学习率过大,那就有可能跳过最优解,进入无限的训练中。解决的方法就是,学习率也需要随着训练的进行而变化
网络训练中的三个概念
- Epoch:训练的轮数
- batch:每次训练每批次样本数量
- iter:使用一个 batch 数据对模型进行一次参数更新的过程
反向传播(BP算法)
前向传播:指的是数据输入到神经网络中,逐层向前传播,一直运算到输出层为止
反向传播(Back Propagation):利用损失函数 ERROR 值,从后往前,结合梯度下降算法,依次求各个参数的偏导,并进行参数更新。反向传播算法通过利用链式法则对神经网络中的各个节点的权重进行更新
梯度下降的优化方法
梯度下降优化算法中,可能会碰到以下情况
- 遇到平缓区域,梯度值较小,参数优化变慢
- 遇到“鞍点”,梯度为 0,参数无法优化
- 遇到局部最小值,参数不是最优
对于说这些问题,有一些优化方法:Momentum、AdaGrad、RMSProp、Adam
其中,动量法 Momentum 对梯度入手,自适应学习率 AdaGrad,RMSProp 对学习率入手,自适应动量法 Adam 对二者都入手
指数(移动)加权平均:该方法不是梯度下降优化方式,而是 动量法:Momentum,自适应学习率:AdaGrad,RMSProp, 自适应动量法:Adam 的底层公式的基础
我们最常见的算数平均指的是将所有数加起来除于个数,每个数的权重是相同的。指数加权平均指的是给每个数赋予不同的权重求得平均数。移动平均数,指的是计算最近邻的 N 个数来获得平均数,距离越远的权重越小,越近的权重越大 $$ S_t= \begin{cases} &Y_1,\ \ \ &t=0\\ \beta*S_{t-1}+(1-\beta)*&Y_t, \ \ \ &t>0 \end{cases} $$
- St 代表指数加权平均值
- Yt 表示 t 时刻的梯度
- β 调节权重系数,该值越大平均数越平缓,β 一般为 0.9 ,值越大,当前梯度影响越小,指数加权平均值影响越大
Momentum:
利用指数加权平均来跨过鞍点
AdaGrad:
AdaGrad 通过对不同的参数分量使用不同学习率,AdaGrad 的学习率总体会逐渐减小
缺点:可能使学习率过早、过量的降低,导致模型训练后期学习率太小,较难找到最优解
RMSProp:
RMSprop 优化算法是对 AdaGrad 的优化。最主要不同是,使用指数加权平均梯度替换历史梯度的平方和
Adam(Adaptive Moment Estimation,自适应矩估计):
Adam 将 Momentum 和 RMSProp 算法结合在一起
梯度计算公式: $$ m_t=\beta_1m_{t-1}+(1-\beta_1)g_t\\ s_t=\beta_2s_{t-1}+(1-\beta_2)g_t^2\\ \hat m_t=\frac{m_t}{1-\beta_1^t}\ \ \ \ \hat s_t=\frac{s_t}{1-\beta_2^t} $$ 权重参数更新公式: $$ w_t=w_{t-1}-\frac{\eta}{\sqrt{\hat s_t}+\varepsilon}\hat m_t $$
| 优化算法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| SGD | 简单,容易实现 | 收敛速度慢,容易震荡,特别是在复杂问题中 | 用于简单任务或者数据特征分布相对稳定 |
| Momentum | 可以加速收敛,减少震荡,特别是在高曲率区域 | 需要手动调整动量超参数,可能会在小步长训练中过度更新 | 用于非平稳优化问题,尤其是深度学习中的应用 |
| AdaGrad | 自适应调整学习率,适用于稀疏矩阵 | 学习率会在训练过程中逐渐衰减,可能导致早期停滞 | 适合稀疏数据,如 NLP 或推荐系统中的特征 |
| RMSProp | 解决 AdaGrad 学习率过早衰减的问题,适应性强 | 需要选择合适的超参数,更新可能会过于激进 | 适用于动态问题,非平稳目标函数,如深度学习训练 |
| Adam | 结合 Momentum 和 RMSProp 的优点,适应性强且稳定 | 需要调节更多的超参数,训练过程中可能会产生较大波动 | 广泛适用于各种深度学习任务,特别是非平稳和复杂问题 |
学习率优化
在训练神经网络时,一般情况下学习率都会随着训练而变化。在神经网络训练的后期,如果学习率过高,会造成loss的振荡,但是如果学习率减小的过慢,又会造成收敛变慢的情况,因此我们可以手动调整学习率
等间隔学习率衰减:lr_scheduler.StepLR(optimizer, step_size, gamma)
下图的 step_size(间隔轮数) 为 50,gamma(学习率衰减系数) 为 0.5
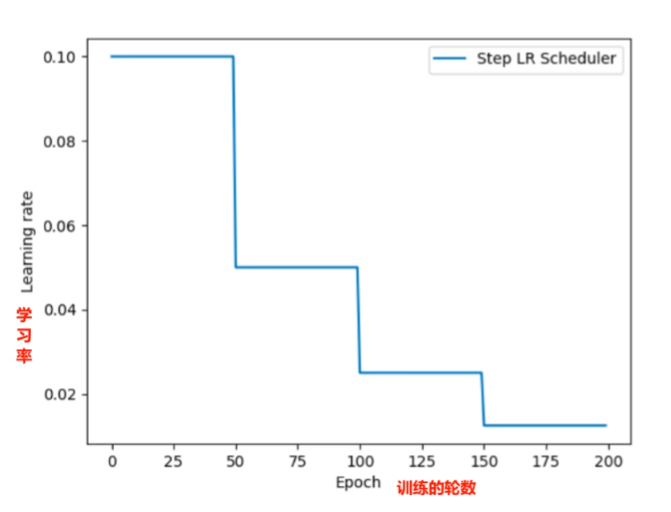
指定间隔学习率衰减 lr_scheduler.MultiStepLR(optimizer, milestones, gammas )
相比于等间隔衰减,milestones 参数可以指定轮次衰减
指数学习率衰减 lr_scheduler.ExponentialLR(optimizer, gamma)
lr = lr ⋅ γepoch,先快后慢
方法 等间距学习率衰减(StepLR) 指定间距学习率衰减(MultiStepLR) 指数学习率衰减(ExponentialLR) 衰减方式 固定步长衰减 指定步长衰减 平滑指数衰减 实现难度 简单易实现 相对简单,容易调整 需要额外历史计算,较复杂 适用场景 大型数据集、较为简单的任务 对训练平稳性要求较高的任务 高精度训练,避免收敛过快 优点 直观,易于调试,适用于大批量数据 易于调试,稳定训练过程 平滑且考虑历史更新,收敛稳定性较强 缺点 学习率变化较大,可能跳过最优点 在某些情况下可能衰减过快,导致优化提前停滞 超参数调节较为复杂,可能需要更多计算资源
正则化方法
神经网络强大的表示能力经常遇到过拟合,所以需要使用不同形式的正则化策略
目前使用较多的策略有:范数惩罚、Dropout、特殊的网络层
Dropout正则化
Dropout(随机失活) 是在训练过程中让神经元以超参数 p 的概率停止工作或者激活被重置为 0,未被重置为 0 的进行缩放,比例为 $\frac{1}{1-p}$。训练过程可以认为是对完整的神经网络的一些子集进行训练,每次基于输入数据只更新子网络的参数。在测试过程中,随机失活不生效
在实际应用中,p 的取值通常在 [0.2, 0.5] 之间,对于较小的模型或较复杂的任务,p 可以选择 0.3 或更小。对于非常深的网络,较大的 p(0.5/0.6) 可能会有效的防止过拟合。通常会在全连接层(激活函数后)之后添加 Dropout 层
批量归一化
先对数据标准化,再对数据重构(缩放+平移) $$ f(x)=\lambda\cdot\frac{x-E(x)}{\sqrt{Var(x)}+\varepsilon}+\beta $$
- λ 和 β 是可学习的参数,它相当于对标准化后的值做了一个线性变换,λ 为缩放系数, β 为偏置
- ε 通常为 10 − 5 ,避免分母为 0
- E(x) 表示变量的均值
- Var(x) 表示变量的方差
批量归一化层在计算机视觉领域使用较多
ANN案例
按照四个步骤来完成
- 准备训练集数据
- 构建要使用的模型
- 模型训练
- 模型预估评测
1 | |
调优策略
- 优化方法采用 Adam
- 减小学习率
- 对数据标准化
- 增加网络深度,每层神经元的个数
- 调整训练的轮数
CNN
卷积神经网络(Convolutional Neural Network)是含有卷积层的神经网络,卷积层的作用就是用来自动学习、提取图像的特征,主要由三部分组成:卷积层、池化层和全连接层
- 卷积层负责提取图像中的局部特征
- 池化层用来大幅降低参数量级(降维)
- 全连接层用来输出结果
卷积层
卷积层的主要作用如下:
- 特征提取:卷积层的主要作用是从输入图像中提取低级特征(如边缘、角点、纹理等)。通过多个卷积层的堆叠,网络能够逐渐从低级特征到高级特征(如物体的形状、区域等)进行学习
- 权重共享:在卷积层中,同一个卷积核在整个输入图像上共享权重,这使得卷积层的参数数量大大减少,减少了计算量并提高了训练效率
- 局部连接:卷积层中的每个神经元仅与输入图像的一个小局部区域相连,这称为局部感受野,这种局部连接方式更符合图像的空间结构,有助于捕捉图像中的局部特征
- 空间不变性:由于卷积操作是局部的并且采用权重共享,卷积层在处理图像时具有平移不变性。也就是说,不论物体出现在图像的哪个位置,卷积层都能有效地检测到这些物体的特征
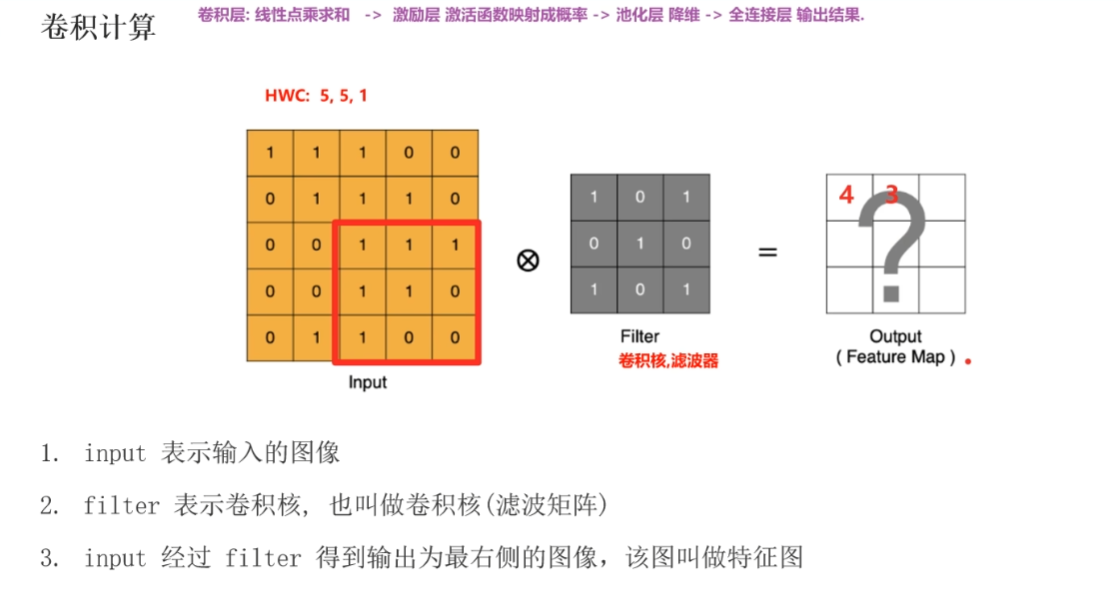
一个卷积核就是一个神经元
填充(Padding)
通过上面的卷积计算过程,最终的特征图比原始图像小很多,如果想要保持经过卷积后的图像大小不变,可以在原图周围添加padding来实现 padding(填充)操作用于处理卷积时图像边缘的像素。其目的是在输入图像的边界周围添加额外的像素(通常是零),从而解决卷积操作时边缘信息丢失的问题
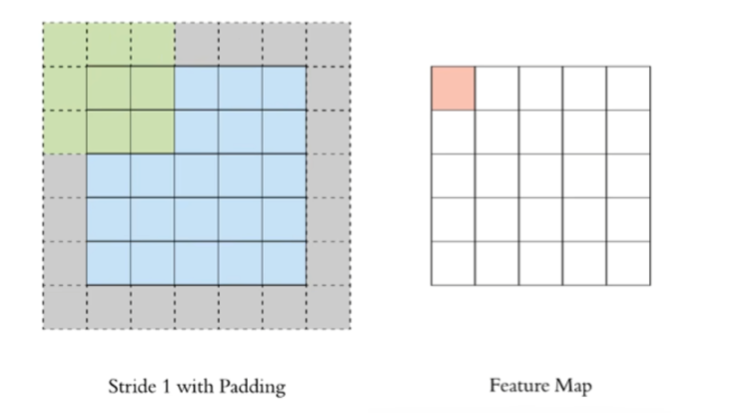
作用:
- 保持空间维度:如果不使用padding,每次卷积操作后,特征图的尺寸都会缩小。多次卷积后,特征图会变得非常小,可能会丢失重要的边缘信息。Padding可以帮助维持输出特征图的尺寸与输入相同或接近相同
- 保留边缘信息:图像边缘的像素在卷积过程中参与的计算次数较少,这意味着边缘信息在特征提取过程中容易丢失。Padding通过在边缘添加额外的像素,增加了边缘像素的参与度,从而更好地保留了边缘信息
- 提高性能:Padding有助于避免由于特征图尺寸快速缩小而导致的信息丢失,从而提高模型的性能,尤其是在处理较小的图像或需要进行多层卷积时
步长(Stride)
stride(步长)指的是卷积核在图像上滑动时的步伐大小,即每次卷积时卷积核在图像中向右(或向下)移动的像素数。步长直接影响卷积操作后输出特征图的尺寸,以及计算量和模型的特征提取能力
作用:
- 降低计算复杂度:更大的步长意味着卷积核移动的次数更少,从而减少了计算量,并加快了训练和推理速度
- 增大感受野:虽然更大的步长会减小特征图的尺寸,但它同时也会增大每个神经元在输入数据上的感受野。这意味着每个神经元能够捕捉到更大范围的输入信息
多通道卷积计算
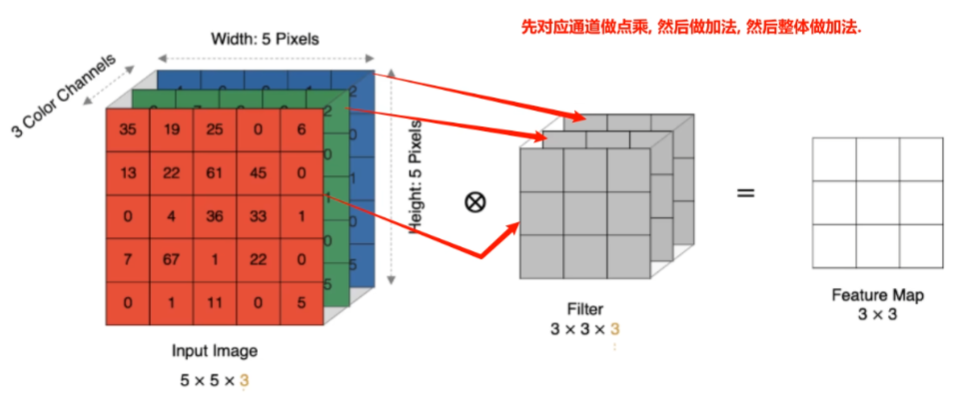
多卷积核卷积计算
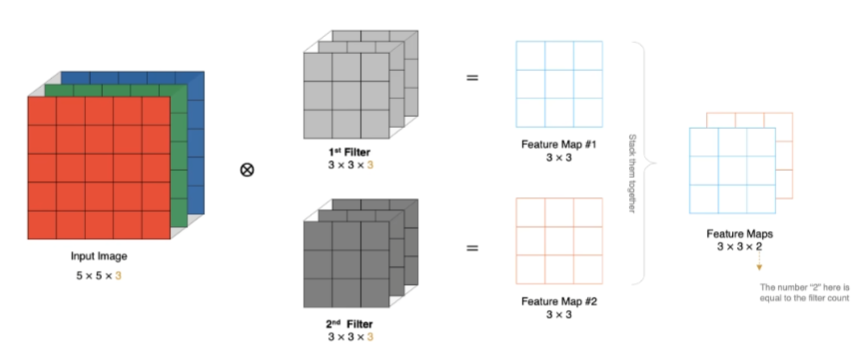
特征图大小
计算公式:$N=\frac{W-F+2P}{S}+1$
- 特征图大小(N)
- 原图大小(W)
- 卷积核大小(F)
- 填充(P)
- 步长(S)
- 例: 原图 5 * 5 ,卷积核 3 * 3,填充 0,步长 1,特征图为 $\frac{5-3+2*0}{1}+1=3\Rightarrow3*3$ 。原图 5 * 7,卷积核 3 * 3,填充 0,步长 1,特征图为 $\frac{5-3+2*0}{1}+1=3,\frac{7-3+2*0}{1}+1=5\Rightarrow3*5$
卷积层的API
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
- in_channels:输入通道数,RGB图片一般为 3
- out_channels:输出通道数(类似输出神经元个数)
- kernel_size:卷积核大小(3 * 3 / 5 * 5 …)
- stride, padding:同前文
池化层
降低维度,从而减少计算量、减少内存消耗,并提高模型的鲁棒性
在处理多通道输入数据时,池化层对每个输入通道进行分别池化,而不是像卷积层那样将各个通道的输入相加。这意味着池化层的输出和输入的通道数是相等的
池化API
- 最大池化 nn.MaxPool2d(kernel_size= 2, stride= 2, padding = 1
- 平均池化 nn.AvgPool2d(kernel_size= 2, stride= 1, padding= 1
案例(CIFAR10)
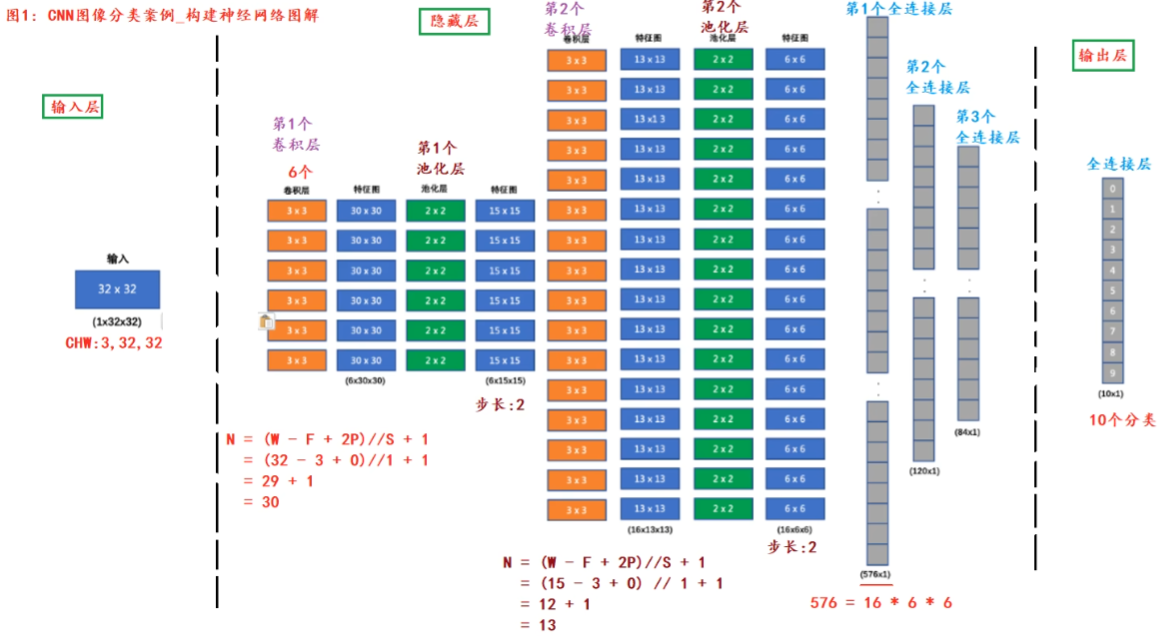
卷积层参数计算公式:输入通道数 * 卷积核尺寸 * 卷积核数量 + 卷积核数量
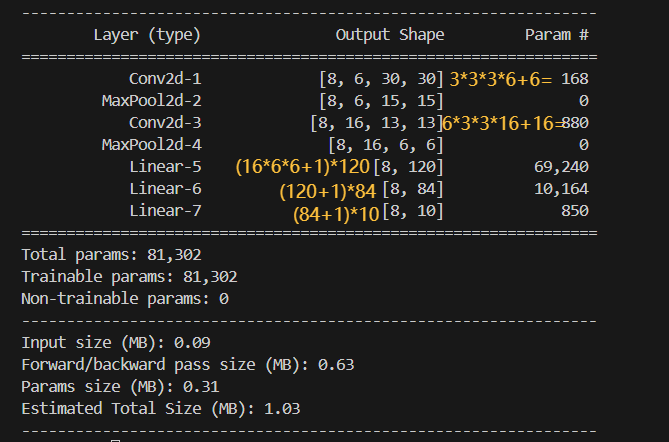
1 | |