机器学习
特征工程
特征提取 sklearn.features_extraction
字典特征提取
1
2from sklearn.features_extraction import DictVectorizer
features = DictVectorizer().fit_transform(datas)文本特征提取
1
2
3
4
5
6
7
8
9
10
11
12
13from sklearn.feature_extraction.text import CountVectorizer
features = CountVectorizer().fit_transform(datas)
# 中文分词使用 jieba 库
import jieba
def cut(text):
return " ".join(jieba.cut(text))
print(cut("我爱北京天安门"));
# Tfidf
from sklearn.features_extraction.text import TfidfVectorizer
features = TfidfVectorizer().fit_transform(datas)无量纲化
- 归一化 MinMaxScaler
- 标准化 StanderScaler
独热编码
降维
1.低方差过滤
1
2
3
4from sklearn.feature_selection import VarianceThreshold
features = VarianceThreshold().fit_transform(datas)
# VarianceThreshold(threshold= x)
# x为整数,删除方差≤x的特征2.主成分分析
1
2
3from sklearn.decomposition import PCA
features = PCA().fit_transform(datas)
# x为整数时,则减少到x个特征, 如果为小数,则保留百分比数据
机器学习
转换器和估计器
- 转换器(transformer) - 特征工程的父类
- 估计器(estimator) - 机器学习算法的实现
模型选择与调优
交叉验证 (cross validation):将训练数据,分为训练和验证集。以下图为例:将数据分为4份,其中一份作为验证集,经过4次(组)的测试,每次更换不同的验证集,即得到4组模型的结果,取平均值作为最终结果,又称4折交叉验证

超参数搜索-网格搜索 (Grid Search):通常情况下,有很多参数需要手动指定 (如KNN),这种叫超参数。手动过程繁杂,所以需要对模型预设几种超参数组合。每组超参数都采用交叉验证来进行评估。最终选出最优参数组合建立模型
API:
1
2
3
4
5
6
7
8
9
10from sklearn.model_selection import GridSearchCV
# GridSearchCV中包含三个参数, estimator, param_grid, cv
# estimator 为估计器
# param_grid 为估计器参数,如(dict){"n_neighbors":[1, 3, 5]}
# cv 指定几折交叉验证
# 详细例子请看下文 KNN算法样例
# tips: 网格搜索每次都会进行标准化,如果之前标准化过,就会导致数据泄露,影响正确性
# estimator = Pipeline([('scaler', StanderScaler()), ('sgd', SGDRegressor(fit_intercept= True))])
# param_dict = {"sgd__eta0": [1e-2, 1e-3, 1e-4]}
# estimator = GridSearchCV(estimator= estimator, param_dict, cv= 4)
用于分类的估计器 (目标是类型)
KNN算法(K-近邻算法):
核心思想:根据邻居来分类
定义:如果一个样本在特征空间中的k个最相似(即特征空间中最临近)的样本中大多数属于某一个类别,则该样本也属于这个类别
距离:确定邻居可以使用欧氏距离(或曼哈顿距离,明可夫斯基距离)
确定 k 的大小:过小的 k 受异常值影响大, 过大的 k 会受到样本不均衡的影响
API:
1
2
3
4from sklearn.neighbors import KNeighborsClassifier
model = KNeighborsClassifier(n_neighbors= 5, algorithm= "auto"
# n_neighbors: int,默认为5 表示上文的 k
# algorithm: {'auto', 'ball_tree', 'kd_tree', 'brute'}总结:优点:简单,易于理解,易于实现 缺点 :计算量大,内存开销大,k 的选择影响大
使用场景:小数据场景,几千到几万的样本
样例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import GridSearchCV
iris = load_iris()
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size= 0.25, random_state= 6)
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
estimator = KNeighborsClassifier()
# 网格搜索 + 交叉验证 注意数据泄露问题
# param_dict = {"n_neighbors": [1, 3, 5, 7, 9, 11]}
# GridSearchCV(estimator, param_grid= param_dict, cv= 10)
estimator.fit(x_train, y_train)
y_pred = estimator.predict(x_test)
print(f"Score: {estimator.score(x_test, y_test)}")
朴素贝叶斯算法:
朴素:假设特征与特征之间是相互独立的
核心思想:基于朴素的贝叶斯算法
拉普拉斯平滑系数:避免概率为0 $P(F1|C)=\frac{N_i+\alpha}{N+\alpha m}$ 其中 α 为系数,一般为
1,m 为文档统计出的特征词个数API:
1
2
3from sklearn.naive_bayes import MultinomialNB
# MultinomialNB(alpha= 1.0)
# 参数解释同上总结:优点:发源于古典数学理论,有稳定的分类效率,对缺失不太敏感,算法简单,常用于文本分类,分类准确度高,速度快 缺点:使用了样本属性独立性的假设,特征属性有关联时效果不好
应用场景:文本分类
样例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.datasets import fetch_20newsgroups
from sklearn.naive_bayes import MultinomialNB
news = fetch_20newsgroups(subset= "all")
x_train, x_test, y_train, y_test = train_test_split(news.data, news.target, test_size= 0.2, random_state= 42)
transfer = TfidfVectorizer()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
estimator = MultinomialNB()
estimator.fit(x_train, y_train)
print(f"准确率: {estimator.score(x_test, y_test)}")
# 准确率: 0.8474801061007957
决策树:例如银行决定是否给一个人贷款时,可以有如下决策树
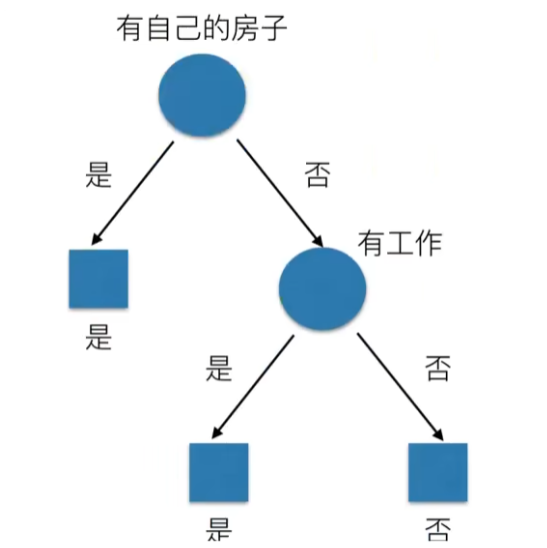
原理:信息熵,信息增益等
信息熵的定义:H(X) = − Σi = 1nP(xi)log p(xi),单位:比特
决策树的划分依据之一 —— 信息增益:特征 A 对训练集 D 的信息增益 g(D, A),定义为集合 D 的信息熵 H(D) 与特征 A 给定条件下 D 的信息条件熵 H(D|A) 之差,公式为: g(D, A) = H(D) − H(D|A)
决策树的划分依据还有:ID3,C4.5,CART
API:
1
2
3
4
5from sklearn.tree import DecisionTreeClassifier
DecisionTreeClassifier(criterion= "gini", max_depth= None, random_state= None)
# criterion 划分依据,默认是 gini,也可以选择信息增益的熵 entropy
# max_depth 树的深度大小 tips: 过大的树会导致 过拟合
# random_state 随机数种子决策树的可视化:
1
2from sklearn.tree import export_graphviz
export_graphviz(decision_tree= estimator, out_file= "./tree.dot", feature_names= ['',''])借助网站 http://webgraphviz.com 来查看
总结:优点:简单的理解和解释,树可视化,可解释性强 缺点: 可能创建不能很好地推广数据的过于复杂的树,引起过拟合 改进:剪枝cart算法,随机森林
案例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27import pandas as pd
from sklearn.feature_extraction import DictVectorizer
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier, export_graphviz
datas = pd.read_csv("https://hbiostat.org/data/repo/titanic.txt")
features = datas[['pclass', 'age', 'sex']]
targets = datas['survived']
features['age'] = features['age'].fillna(features['age'].mean())
features = features.to_dict(orient= "records")
x_train, x_test, y_train, y_test = train_test_split(features, targets, test_size= 0.2, random_state= 24)
transfer = DictVectorizer()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
# 此处可以使用网格搜索来限制深度,从而达到更好的结果
estimator = DecisionTreeClassifier(criterion= "entropy")
estimator.fit(x_train, y_train)
print(estimator.score(x_test, y_test))
# 0.8022813688212928
export_graphviz(estimator, out_file= "titanic.dot", feature_names= transfer.get_feature_names_out())
随机森林(集成学习方法):
定义:随机森林是一个包含多个决策树的分类器,输出的类别是由个别树输出的类别的众数而定
建造树的方法:
- 训练集随机 —— 从 N 个样本中随机有放回的抽样 N 个
- bootstarp 随机有放回抽样
- 例如:[1, 2, 3, 4 ,5] -> [2, 2, 3, 1, 5]
- 特征随机 —— 从 M 个特征中随机抽取 m 个特征
- M > > m 降维,防止过拟合
- 训练集随机 —— 从 N 个样本中随机有放回的抽样 N 个
API:
1
2
3
4
5
6
7
8
9
10from sklearn.ensemble import RandomForestClassifier
RandomForestClassifier(n_estimators= 10, criterion= "gini", max_depth= None, bootstrap= True, random_state= 24, min_samples_split= 2)
# 部分参数和决策树相同
# n_estimators 森林里树的数量
# max_features 每个决策树的最大特征数量,默认为 'auto'
# 'sqrt'(auto) / 'log2' / 'None'
# bootstrap 解释同上文
# min_sample_split 节点划分最少样本数
# min_sample_leaf 叶子节点最小样本数
# 超参数: n_estimators, max_depth, min_sample_split, min_sample_leaf总结:在当前所有算法中,具有较好的准确率。能有效运行在大数据集上,处理具有高维特征的输入样本,而且不需要降维。能够评估各个特征在分类问题上的重要性
回归和聚类算法
线性回归(Linear regression):
定义:利用回归方程(函数)对一个或多个自变量(特征值)和因变量(目标值)之间关系进行建模的一种分析方式
特点:只有一个自变量的情况称为单变量回归,多于一个自变量的情况称为多元回归
通用公式:h(w) = w1x1 + w2x2 + ⋯ + b = wTx + b
线性关系一定是线性模型,线性模型不一定线性关系
损失函数(成本函数)优化:
- 正规方程: w = (XTX) − 1XTy 数学上的精确解
- 优点:可以直接求到最好的结果
- 缺点:当特征过多过复杂时,求解速度慢且得不到结果
- 数据量较小可以使用 < 100K
- 梯度下降 不标准化可能无法收敛
- 数据量较大可以使用 > 100K
- 优化方法:
- GD(Gradient Descent) 最原始的梯度下降算法
- SGD(Stochastic Gradient Descent) 随机梯度下降
- 优点:高效,容易实现
- 缺点:需要许多超参数,对特征标准化敏感
- SAG(Stochastic Average Gradient) 随机平均梯度法
- 使用网格搜索超参数时,务必使用pipeline进行标准化,否则会无法收敛
- 正规方程: w = (XTX) − 1XTy 数学上的精确解
API:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15from sklearn.linear_model import LinearRegression
LinearRegression(fit_intercept= True)
# fit_intercept 是否计算偏置
# LinearRegression.coef_ 回归系数
# LinearRegression.intercept_ 偏置
from sklearn.linear_model import SGDRegressor
SGDRegressor(loss= "squared_loss", fit_intercept= True, learning_rate= "invscaling", eta0= 0.01)
# SGDRegressor 采用随机梯度下降学习,支持不同loss函数和正则化惩罚来拟合
# loss 损失函数 "squared_loss" 最小二乘法(默认)
# learning_rate 学习率填充
# 'constant': eta = eta()
# 'optimal': eta = 1.0 / (alpha * (t + t0)) (默认)
# 'invscaling': eta = eta0 / pow(t, power_t) power_t = 0.25 存在父类中
# 同理也有回归系数和偏置项的api模型评估:sklearn.metrics
- 均方误差(MSE): $MSE=\frac{1}{m}\sum_{i=1}^m(y_i-\bar y)^2$
- 平均绝对误差(MAE)
- 决定系数 (R2)
- 均方根误差 (RMSE)
过拟合与欠拟合:
欠拟合:原因:学习到的特征过少 解决:增加数据特征数量
过拟合:原因:原始特征过多,存在一些嘈杂特征,模型过于复杂 解决:
正则化类别
L2正则化(最常用)
- 作用:可以使其中一些 w 变小,削弱某个特证影响
- 优点:越小的参数说明模型越简单,越简单的模型越不容易出现过拟合现象
- Ridge回归
- 加入L2正则化后的损失函数:
$$ J(w)=\frac{1}{2m}\sum_{i=1}^m(h_w(x_i)-y_i)^2+\lambda \sum_{j=1}^{n}w_j^2 $$
- 其中 $\lambda \sum_{j=1}^n w_j^2$ 为惩罚项,m 为样本数, n 为特征数, λ 为步长,可以超参数
L1正则化
- 和 L2正则化相似,都在损失函数后加入惩罚项
- 惩罚项为:$\lambda \sum_{j=1}^n |w_j|$
- 作用:可以使得其中的 w 直接变为 0,删除某个特征影响
- LASSO回归
岭回归(Ridge):
带有L2正则化的线性回归
API:
1
2
3
4
5
6from sklearn.linear_model import Ridge
Ridge(alpha= 1.0, fit_intercept= True, solver= "auto")
# alpha 正则化力度 即上文的 lambda 0~1, 1~10, 可超参数
# solver 优化方法
# 在大数据集的情况下采用 SAG
# 同理也有回归系数和偏置项Ridge相当于SGD加上了L2正则化,但Ridge实现了SAG
正则化力度越大,权重系数越小,反之,正则化力度越小,权重系数越大
逻辑回归 (Logistic Regression): 解决二分类问题
tips:虽然带有“回归”,但逻辑回归是一种分类算法,只是它与回归之间有一定联系
线性回归的输出就是逻辑回归的输入,即 h(w) = w1x1 + w2x2 + w3x3 + ⋯ + b 为输入
激活函数:
- Sigmoid 函数: $g(\theta^Tx)=\frac{1}{1+e^{-\theta^Tx}}$ 将某个函数映射到 [0, 1] 区间内
损失:对数似然损失 $$ cost(h_\theta(x),y)= \begin{cases} -\log(h_\theta(x))\ \ \ \ \ &if\ \ y=1\\ -\log(1-h_\theta(x))\ \ \ \ &if\ \ y=0 \end{cases} $$
完整损失函数: $cost(h_\theta(x), y)=\sum_{i=1}^{m}-y_i\log(h_\theta(x))-(1-y_i)\log(1-h_\theta(x))$
损失优化:梯度下降
API:
1
2
3
4
5
6
7from sklearn.linear_model import LogisticRegression
LogisticRegression(solver= "liblinear", penalty= "l2", C= 1.0)
# solver 优化求解方式
# liblinear 默认开源库,坐标轴下降法
# sag 同上文
# penalty 正则化
# C 正则化力度案例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43# 数据集下载链接https://archive.ics.uci.edu/dataset/15/breast+cancer+wisconsin+original
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import roc_auc_score
column_names = ['Sample code number', 'Clump Thickness', 'Uniformity of Cell Size', 'Uniformity of Cell Shape',
'Marginal Adhesion', 'Single Epithelial Cell Size', 'Bare Nuclei', 'Bland Chromatin',
'Normal Nucleoli', 'Mitoses', 'Class']
datas = pd.read_csv("./breast-cancer-wisconsin.data", names= column_names)
datas = datas.replace(to_replace= "?", value= np.nan)
datas = datas.dropna()
x_train, x_test, y_train, y_test = train_test_split(datas.iloc[:, :-1], datas['Class'], test_size= 0.2, random_state= 24)
transfer = StandardScaler()
x_train = transfer.fit_transform(x_train)
x_test = transfer.transform(x_test)
estimator = LogisticRegression(penalty= "l2")
estimator.fit(x_train, y_train)
print(estimator.score(x_test, y_test))
# 0.9562043795620438
# 模型评估,详见下文
from sklearn.metrics import classification_report
print(classification_report(y_test, estimator.predict(x_test), labels= [2, 4], target_names= ['良性', '恶性']))
# precision recall f1-score support
#
# 良性 0.96 0.98 0.97 88
# 恶性 0.96 0.92 0.94 49
#
# accuracy 0.96 137
# macro avg 0.96 0.95 0.95 137
# weighted avg 0.96 0.96 0.96 137
# ROC,AUC 详见下文
y_test = np.where(y_test > 3, 1, 0)
print(roc_auc_score(y_test, y_pred))
# 0.9478200371057514模型评估:
精确率和召回率:
- 混淆矩阵

- 精确率(Precision):预测结果为正例样本中真实为正例的比例 $P_1=\frac{TP}{TP+FP}$
- 召回率(Recall):真实结果为正例的样本中预测结果为正例的比例 $P_2=\frac{TP}{TP+FN}$
- F1-Score:反应了模型的稳健性 $F1=\frac{2TP}{2TP+FN+FP}=\frac{2\cdot P_1\cdot P_2}{P_1+P_2}$
API:
1
2from sklearn.metrics import classification_report
classification_report(y_true, y_pred, labels= [], target_names= None)
样本不均衡情况下的评估 —— ROC曲线和AUC指标
TPR与FPR
- $TPR=\frac{TP}{TP+FN}$ 所有真实类别为 1 的样本中,预测类型为 1 的比例
- $FPR=\frac{FP}{FP+TN}$ 所有真是类别为 0 的样本中,预测类型为 1 的比例
ROC曲线
- 定义:ROC曲线横轴为 FPR , 纵轴为 TPR ,当二者相等时,对于不论真实类别是 1 还是 0 的样本,分类器预测为 1 的概率是相等的,此时的 AUC 为 0.5
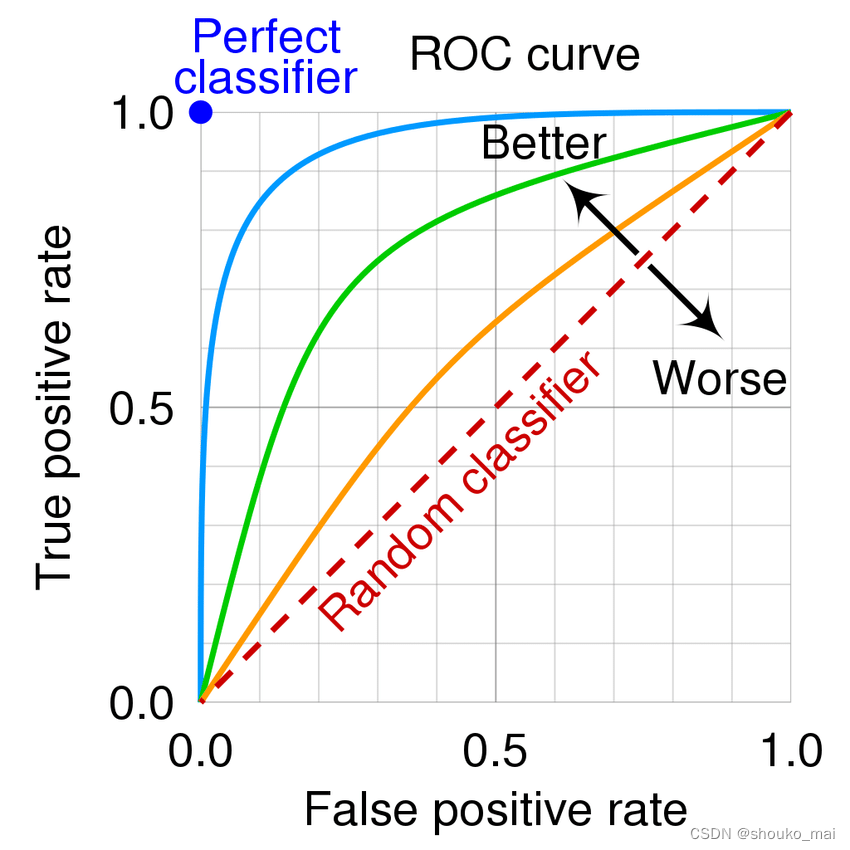
- 定义:ROC曲线横轴为 FPR , 纵轴为 TPR ,当二者相等时,对于不论真实类别是 1 还是 0 的样本,分类器预测为 1 的概率是相等的,此时的 AUC 为 0.5
AUC指标
AUC 的概率意义是随机取一对正负样本,正样本得分大于负样本的概率
AUC 的值域一般在 [0.5, 1],数值越大越好
AUC = 1 ,完美分类器,采用这个分类器时,不管设定什么阈值都能得到完美预测。绝大多数预测的场合,不存在完美分类器
0.5 < AUC < 1, 优于随机猜测,当这个分类器妥善设置阈值时,有预测价值
如果 AUC 指标小于 0.5,可以反过来看(模型的对立面)
API:
1
2
3
4from sklearn.metrics import roc_auc_score
roc_auc_score(y_true, y_score)
# y_true 每个样本的真实类别
# y_score 预测得分,可以是正类的估计概率,置信值或者分类器方法的返回值总结: AUC 只能用来评价二分类,非常适合评价样本不均衡中的分类器性能
无监督学习——K-means算法
没有目标值->无监督学习
包含:聚类(K-means),降维(PCA)
原理:
- 随机设置 k 个特征空间内的点作为初始的聚类中心
- 对于其他每个点计算到 k 个中心的距离,未知的点选择最近的一个聚类中心点作为标记类别
- 接着对着标记的聚类中心之后,重新计算出每个聚类的新中心点(平均值)
- 如果计算得出的新中心点与原中心点一样,就结束,否则重复上述过程
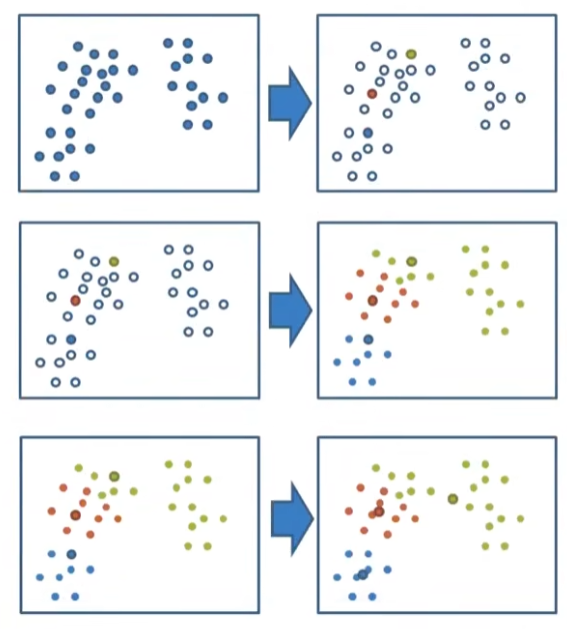
k 可以进行超参数
API:
1
2
3
4from sklearn.cluster import KMeans
KMeans(n_clusters= 8, init= "k-means++")
# n_clusters 同上文 k
# init 初始化方法 默认为 k-means模型评估:
轮廓系数:bi 为 i 到其他族群的所有样本的距离最小值,ai 为 i 到本身簇的距离平均值 $$ SC_i=\frac{b_i-a_i}{max(b_i,a_i)} $$
“高内聚,低耦合”
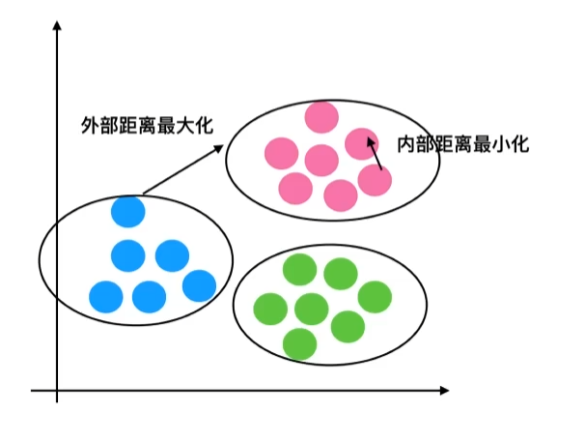
轮廓系数的值越接近 1 效果越好, 越接近 -1 效果越不好
API:
1
2
3
4from sklearn.metrics import silhouette_score
silhouette_score(X, labels)
# X 特征值
# labels 目标值
总结:特点分析:采用迭代式算法,直观易懂且实用 缺点:容易收敛到局部最优解(多次聚类)
模型的保存与加载
API:
1
2
3import joblib
joblib.dump(estimator, 'test.pkl')
# estimator = joblib.load('test.pkl')